Coarse-Grain Reconfigurable Arrays
Need for faster and power-efficient processors has paved the way for many-core processors along with considerable research in accelerators. Acceleration through popular Graphics Processing Units (GPUs) is over a broad range of the parallel applications but majorly limited to massively parallel loops and loops with high trip counts. Field programmable gate arrays (FPGAs) on the other hand, are reconfigurable and general-purpose but are marred by low power efficiency due to their fine-grain management.
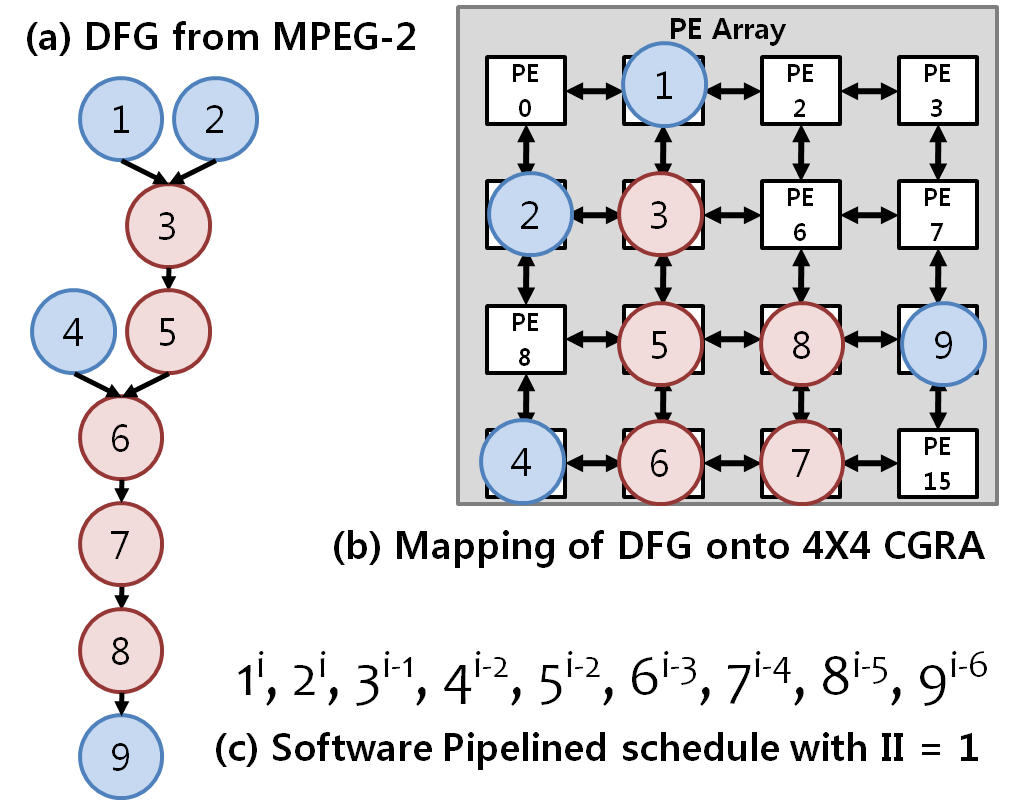
Coarse-Grained Reconfigurable Arrays (CGRAs)are promising accelerators, capable of accelerating even non-parallel loops and loops with lower trip-counts. They are programmable yet, power-efficient accelerators. CGRA is an array of Processing Elements (PE) connected through a 2-D network; each PE contains an ALU-like Functional Unit (FU) and a Register File (RF). FUs are capable of executing arithmetic, logical or even memory operations. At every cycle, each PE gets an instruction from the instruction memory, specifying the operation. The PE may read/write the data from/to data memory; data/address bus are shared either by PEs in the same column or by PEs in the same row. CGRA can achieve higher power efficiency due to simpler hardware and intelligent software techniques. [A Short Video on Executing the Loops on CGRA]
Since CGRA is a simple hardware and all the intelligence and hence the complexity, has been transferred to the software, the compiler should be smart enough to effectively utilize the CGRA resources. One of the widely researched topics in CGRA research is the mapping techniques for CGRAs. Loop to be accelerated is extracted from the application and converted into a Data Dependency Graph (DDG). Problem formulation of the mapping of the DDG onto the target array is NP-complete. Plus, mapping hueristic should be able to generate the mapping with better quality in lower compilation time, as well as it should ensure maximum the usage of the CGRA resources — such as registers, PE units etc.